Chapter 14Eigenvectors and eigenvalues
"Last time, I asked: 'What does mathematics mean to you?', and some people answered: 'The manipulation of numbers, the manipulation of structures.' And if I had asked what music means to you, would you have answered: 'The manipulation of notes?'"
- Serge Lang
Eigenvectors and eigenvalues are some of those topics that a lot of students find particularly unintuitive. Questions like “why are we doing this?” and “what does this actually mean?” are too often left floating away unanswered in a sea of computations. And as I've put out chapters in this series, many of you have commented about looking forward to visualizing this topic in particular.
I suspect that the reason for this is not so much that eigen-things are particularly complicated or poorly explained. In fact, it's comparatively straightforward, and I think most books do a fine job explaining it. The issue is that it only really makes sense if you have a solid visual understanding of many of the topics that precede it. Most important here is that you know how to think about matrices as linear transformations. But you also need to be comfortable with determinants , linear systems of equations, and change of basis. Confusion about eigen-stuffs usually has more to do with a shaky foundation in one of these topics than it does with the eigenvectors and eigenvalues themselves.
An example
To start, consider some linear transformation in two dimensions, like the one shown here.
It moves the basis vector to the coordinates , and to , so it's represented with a the matrix . Now, focus on what it does to any individual vector, and think about the span of that vector, which is the line passing through the origin and its tip.

Most vectors will get knocked off that line during the transformation. It would seem pretty coincidental if the place where a vector lands happens to be somewhere on that line. But some special vectors do remain on their own span, meaning the effect the matrix has on such a vector is to just stretch or squish it, like a scalar.

For this specific example, the basis vector is one such vector with this special property. The span of is the -axis, and from the first column of the matrix we can see that moves over to times itself, still on that -axis. What's more, because of the way linear transformations work, any other vector on the -axis is also just stretched by a factor of , and hence remains on its own span.

A slightly sneakier vector that remains on its own span during this transformation is . It ends up getting stretched out by a factor of . And again, linearity will imply that any other vector on the diagonal line spanned by this one will just get stretched out by a factor of .

For this transformation, those are all the vectors with this special property of staying on their span: Those on the -axis that get stretched by a factor of , and those on this diagonal line that are stretched by a factor of . Any other vector will get rotated somewhat during the transformation, knocked off of the line it spans.

These special vectors are called the "eigenvectors" of the transformation, and each eigenvector has associated with it what's called an "eigenvalue", which is the factor by which it's stretched or squished during the transformation. In this example, vectors on the -axis are eigenvectors with eigenvalue , while those on the diagonal line are eigenvectors with eigenvalue .

Of course, there's nothing special about stretching vs. squishing, or the fact that these eigenvalues happen to be positive. In another example you could have an eigenvector with eigenvalue , meaning that vector gets flipped and squished by a factor of , but the important part is that it stays on the line that it spans out, without being rotated off of it.

Eigenvector with eigenvalue .
3d rotational axis
For a glimpse of why this might be a useful thing to think about, consider some three-dimensional rotation. If you can find an eigenvector for this rotation, a vector which remains on its own span, what you have found is the axis of rotation.

It's much easier to think about a 3d rotation in terms of an axis of rotation, and an angle by which it is rotating, rather than thinking about the full 3x3 matrix associated with such a transformation.


In this case, the corresponding eigenvalue would have to be , since 3d rotations don't stretch or squish anything.
This is a pattern that shows up a lot in linear algebra: With any linear transformation described by a matrix, you could understand what it's doing by reading off the columns of this matrix as the landing spots for the basis vectors. But often a better way to get at the heart of what that transformation actually does, less dependent on your particular coordinate system, is to find the eigenvectors and eigenvalues.
Notes on computation
We won't cover the full details on methods for computing eigenvectors and eigenvalues here, but we'll try to give an overview of the computational ideas that are most important for conceptual understanding.
Symbolically, here's what the idea of eigenvectors and eigenvalues looks like. is the matrix representing some transformation, with as an eigenvector, and (lambda) is a number, namely the corresponding eigenvalue.

What this expression is saying is that the matrix-vector product times gives the same result as scaling the eigenvector by the eigenvalue lambda.

Finding the eigenvectors and eigenvalues of a matrix comes down to finding values of and that make this expression true. It's a little awkward to work with at first, because the left-hand-side represents matrix vector multiplication, while the right-hand-side is scalar-vector multiplication. Let's start by rewriting that right-hand-side as some kind of matrix vector multiplication, using a matrix which has the effect of scaling vectors by a factor of lambda.

The columns of such matrix will represent what happens to each basis vector, and each basis vector is simply multiplied by lambda, so this matrix will have the number lambda down the diagonal with zeros everywhere else. The common way to write this matrix is as lambda times , where is the identity matrix with s down the diagonal.

With both sides looking like matrix-vector multiplication, we can subtract off the right-hand side and factor out the . So we have a new matrix, , and we're looking for a vector such that this new matrix times gives the zero vector.

Now, this will always be true when is the zero vector, but that's boring, we want a non-zero eigenvector.
Zero Determinant
As viewers of chapter 5 and chapter 6 will know, the only way it's possible for the product of a matrix with a nonzero vector to become zero is if the transformation associated with that matrix squishes space into a lower dimension. And that squishification corresponds to a zero determinant of the matrix.
To be concrete, let's say your matrix is , and imagine subtracting off the variable amount lambda from each diagonal entry.

Imagine tweaking lambda, turning a knob to change its value. As that value of lambda changes, the matrix changes, and so the determinant of that matrix changes.

The goal is to find a value of lambda that will make the determinant zero, meaning the tweaked transformation squishes space. In this case, the sweet spot comes when .

Remember that the lambda is tied to the matrix, so if we use another matrix, the lambda might not be . To unravel what that means, when , the matrix squishes space onto a line. That means there's a nonzero vector such that .
The reason we care about that is because it means , which you can read as saying the vector is an eigenvector of , staying on its own span during the transformation . In this example, the corresponding eigenvalue is , so it actually just stays fixed in place.
Pause and ponder to make sure that line of reasoning feels good.
Characteristic polynomial
This expression, where we take a given matrix minus lambda times the identity and set its determinant equal to zero, thinking of lambda as a variable, is fundamental to eigenvalues. This is the kind of thing we mentioned in the introduction. If you didn't have a solid grasp of the determinant, and why it relates to linear systems having non-zero solutions, an expression like this would feel completely out of the blue.
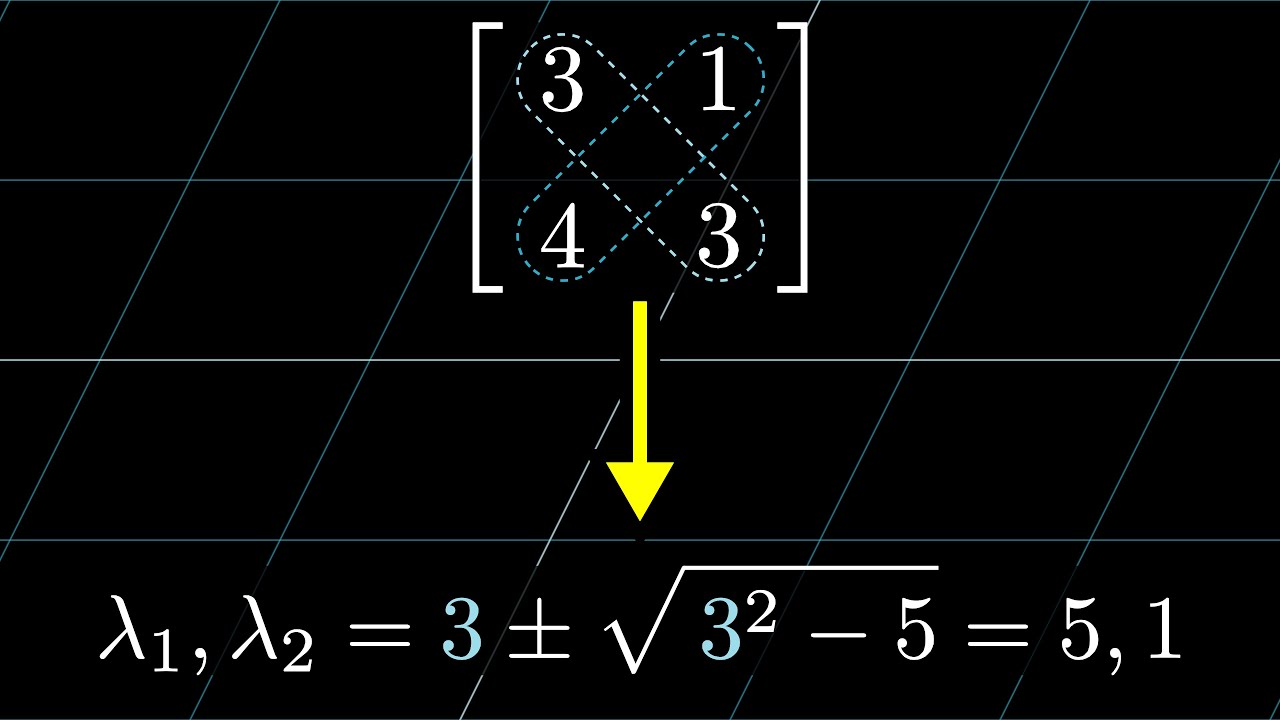
Let's revisit the example from the start, with the matrix .

To find if a value is an eigenvalue, subtract it from the diagonals of this matrix, and compute the determinant.
Doing this, we get a certain quadratic polynomial in terms of lambda.
Since lambda can only be an eigenvalue if this determinant is zero, you can conclude that the only eigenvalues are and . To see what eigenvectors have one of these eigenvalues, say , plug in that value of lambda to the matrix, and solve for which vectors this diagonally-altered matrix sends to zero.
If you computed this, you'd see that the solutions are all of the vectors on the diagonal line spanned by . This corresponds to the fact that the unaltered matrix stretches all those vectors by a factor of .

Rotation
Now, a 2d transformation doesn't have to have eigenvectors. For example, consider a rotation by degrees. This doesn't have any eigenvectors, since each vector is rotated off of its own span.
If you actually try computing the eigenvalues for a degree rotation, notice what happens. Its matrix is . Subtract from the diagonal elements, and look for when the determinant is .
In this case, you get the polynomial . The only roots of this polynomial are the imaginary numbers and . The fact that there are no real number solutions indicates that there are no eigenvectors.
Shear
Another interesting example is a shear. This fixes in place, and moves one over, so its matrix is .
All the vectors on the -axis are eigenvectors with eigenvalue , since they remain fixed in place. In fact these are the only eigenvectors. When you subtract from the diagonals and compute the determinant, you get , and the only root of that expression is .
This lines up with what we see geometrically that all the eigenvectors have eigenvalue .
Scaling
It's also possible to have just one eigenvalue with more than just a line full of eigenvectors. A simple example is the matrix which scales everything by . The only eigenvalue is , but every vector in the plane gets to be an eigenvector with that eigenvalue.
Scale everything by .
Now is another good time to pause and ponder some of this.
Questions
What is the eigenvalue(s) of the matrix ?
What is the eigenvalue(s) of the matrix ?
What is the eigenvalue(s) of the matrix
Working in an eigenbasis
Let's finish off here with the idea of an eigenbasis, which relies heavily on ideas from the last chapter.
Take a look at what happens if our basis vectors happen to be eigenvectors. For example, maybe is scaled by , and is scaled by . Writing their new coordinates as columns of a matrix, notice that those scalar multiples and , which are the eigenvalues of and , are on the diagonal, and all other entries are .

Any time a matrix has zeros everywhere other than the diagonal, it's called a "diagonal matrix", and the way to interpret it is that all the basis vectors are eigenvectors, and the diagonal entries of the matrix give you their corresponding eigenvalues.
There are a number of things that make diagonal matrices nicer to work with. One big one is that it's easier to compute what will happen if you multiply this matrix by itself a whole bunch of times.
Since all one of these matrices does is scale each basis vector by some eigenvalue, applying that matrix, say, 100 times will just correspond to scaling each basis vector by the 100th power of the corresponding eigenvalue.
By contrast, consider how hard computing the 100th power of a non-diagonal matrix would be. Really, think about it for a moment, compared to simply exponentiating the entries it's a nightmare!
Change of basis
Of course, you will rarely be so lucky as to have your basis vectors also be eigenvectors. But if your transformation has lots of eigenvectors, enough that you can choose a set that spans the full space, then you can change your coordinate system so that these eigenvectors are your basis vectors.

We talked all about change of basis in the last chapter, but let's go through a super quick reminder here of how to express a transformation in a different coordinate system.
Take the coordinates of the vectors you want to use as a basis, which in our cases means two eigenvectors, then make those coordinates the columns of a matrix, known as the change of basis matrix. When you sandwich the original transformation, putting the change of basis matrix on its right and the inverse change of basis matrix on its left, the result will be a matrix representing this same transformation, but from the perspective of the new basis vector's coordinate system.

The whole point of doing this with eigenvectors is that this new matrix is guaranteed to be diagonal, with the corresponding eigenvalues down the diagonal, since this represents working in a coordinate system where basis vectors just get scaled during the transformation.

A set of basis vectors which are all also eigenvectors is called an “eigenbasis”. For example, if you needed to compute the 100th power of this matrix, it would be much easier to change to an eigenbasis, compute the 100th power in that system, then convert back to the standard system. You can't do this with all transformations. A shear, for example, doesn't have enough eigenvectors to span all of space. But if you can find an eigenbasis, it can make matrix operations really lovely.
For anyone willing to work through a neat puzzle to see what this looks like in action, and how it can be used to produce surprising results, we'll put the puzzle prompt below. It's a bit of work, but we think you'll enjoy it.
The next chapter is about a quick trick for computing eigenvalues before the final chapter of the series on abstract vector spaces.